Stable diffusionの「ControlNET&拡張機能講座」第25回目。今回は「AnimateDiff」を使って画像を動かす方法です。

こんな感じで2秒ぐらいのがプロンプトの記入だけで作れます。
最近はAI動画の技術も上がっているのニャ。
Stable diffusionに追加機能を入れるだけなので、かなりお手軽になりましたね。
そんなわけで、やり方をさくっと説明していきましょう。用意した画像をImg2Imgで動かす方法も述べています。
前回の「「mov2mov」を使った動画作成をわかりやすく解説」は以下のリンクから。
「AnimateDiff」のインストール
インストール方法
「Stable diffusion」を起動し、「Extensions」タブ→「Install from URL」タブに移動し、「URL for extension’s git repository」に、
https://github.com/continue-revolution/sd-webui-animatediff.git
を貼り付けて、「Install」ボタンをクリックします。しばらく待つと「Install」ボタンの下の方にいろいろ文字が出てきてインストール終了。
つぎに「Extensions」タブ→「Installed」タブで「Apply and restart UI」 ボタンをクリックして再起動します。これでインストール完了です。
注意としては、「Stable diffusion」のバージョンが古いと動きません。かなり長い間アップデートしていない人は、バックアップをとったうえで(フォルダごとどこかにコピーしておいておけばいい)、最新版にしてしまいましょう。
また「AnimateDiff」のインストールによって動作不良を起こす場合もあるため、動画用と画像用で2種類の「Stable diffusion」を用意して使い分けるのもいいとは思います。「AnimateDiff」用に、「Stable diffusion」を最初からインストールし直してもいいとは思います。

それと「xformers」を設定していると動かないという報告がありますが、筆者の環境では動きます。もし動かなかったら「xformers」をいったん外してください。「xformers」については以下のリンクを参照してください。

メモリが厳しい方は、「xformers」を書き込むところに
「–no-half-vae」(真っ黒を防ぐ)
「–medvram」(vram節約。生成速度は落ちる)
*どちらも先頭のハイフンは「2つ」です。
の2つを付け加えてもいいでしょう。
モーションモデルのダウンロード
いったん「Stable diffusion」を終了し、モーションモデルをダウンロードします。

にある
mm_sd_v14.ckpt
mm_sd_v15.ckpt
mm_sd_v15_v2.ckpt
の3つをダウンロードします。
そののち、この3つを「Stable diffusion」をインストールしたフォルダ内の
stable-diffusion-webui>extensions>sd-webui-animatediff>model
のフォルダに入れます。
【追記】
https://huggingface.co/conrevo/AnimateDiff-A1111/tree/main/motion_module
に「mm_sd15_v3.safetensors」があるので、必要ならこれもダウンロードしておきましょう。
以上で準備は終了です。
「AnimateDiff」を使う
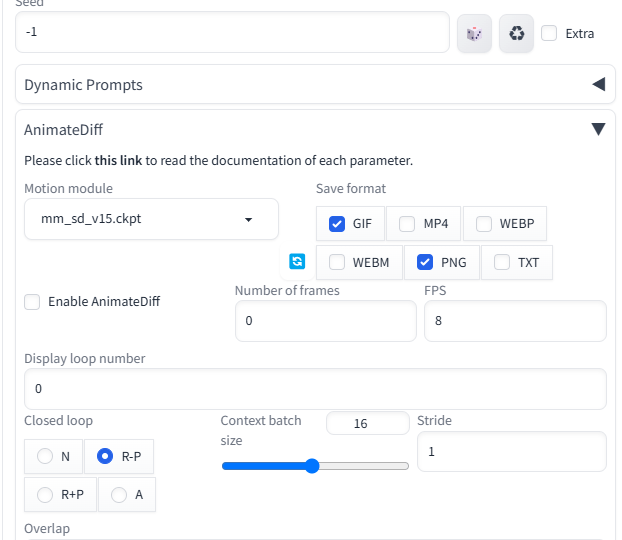
「Stable diffusion」を起動すると、下のほうに「AnimateDiff」が追加されていますので、それを開くと上の画像のようになります。
「Motion module」のところで、先ほど導入した3つのモーションモデルのうち1つを選択します。v14は動きが大きく、v15は動きが小さく、v15_v2はその中間という感じです。とりあえず中間の「mm_sd_v15_v2.ckpt」にしておきましょう。
「Enable AnimateDiff」にチェックを入れると、「AnimateDiff」が使えます。ようするにオンオフボタンですね。画像生成だけしたいときは、ここのチェックを外します。ぶっちゃけこれしか使いません。あとの設定はデフォルトでいいです。
いちおう説明しておくと、「Number of frames」は動画に使われる画像が全部で何枚かということです。デフォルトは0ですが、そのまま実行すれば16枚です。
「Context batch size」は一度に何枚処理するか。デフォルトのままでいいでしょう。
「FPS」は1秒間に何枚かということです。デフォルトは8枚になっているので、1秒に8枚ですね。さっきの16枚と組み合わせると2秒の動画ができるということです。あまり多すぎるとPCへの負荷が大きくなるので、デフォルトの2秒ぐらい(16枚)にしておくのがいいでしょう。
「Display loop number」はループ回数です。0は無限ループです。0のままでいいでしょう。
「Closed loop」はループのさせ方です。デフォルトは「R-P」。「ABCCBA」のように折り返すときは「A」を選択してください(動画サイズは2倍になります)。「N」だとループしません。
とりあえず全部デフォルトのままで、「Enable AnimateDiff」にチェックを入れてから、プロンプトに「cat,best quality, running」と書いてください。プロンプトは75トークン以下にしたほうがいいでしょう。それ以上になると筆者の環境ではエラーを吐き出し、再起動が必要になります。
画像サイズは512×512にしたほうがいいですね。縦長とかにしたい場合も512X720ぐらいにしておいたほうがいいでしょう。ここが大きいとメモリオーバーになったりします。

「Generate」してしばらく待つと、猫が走っているような2秒の動画ができると思います。
粗は多いけど、それっぽいのニャ。
あとはプロンプトいじったりで調整していく形ですね。
できあがった動画は「Stable diffusion」をインストールしたフォルダ内の
stable-diffusion-webui>outputs>txt2img-images>AnimateDiff
に格納されます。
フレーム変化の記述
プロンプトで、
0: Smile,
4: cry,
8: open mouth,
12: close eyes,
のような記述をすると(「:」のあとに半角スペースを入れるのに注意)、「0フレームからスマイル」→「4フレームから泣く」→「8フレームから口を開ける」→1「2フレームから目を閉じる」のように、時間ごとの変化を指定できます。
ただ大きな動きなどはできませんし、かならず変化するわけでありません。
また「Dynamic Prompt」と併用できないので、「Dynamic Prompt」はチェックを外してオフにしておきましょう。

FreeInit Params
本拡張は基本的に16枚で学習しています。そのため、最大フレームを32枚にすると「16枚→16枚」というように2回生成する形になり、前半と後半で整合性が取れない場合があります。これを修正する方法として、「FreeInit Params」があります。
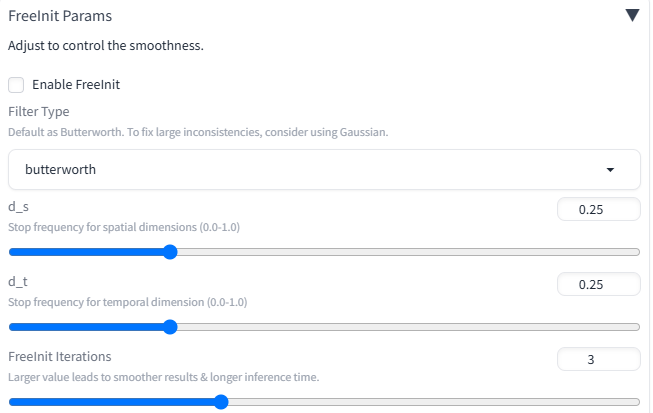
下にある「FreeInit Params」のところを開き、「Enable FreeInit」にチェックを入れて使用します。
一番下の「FreeInit Iterations」がデフォルトで3になっていますが、これは「3回見直せ」ということですね。「16枚→16枚」を生成し、それの整合性が取れているかを3回実行して見直します。そのため3倍の時間がかかるということです。
ただこれをやったからといって整合性が取れるわけではないので、気休めぐらいに思ったほうがいいでしょう。
顔や手を直す
動画だと、顔や手がうまく表現されないことが多くなります。それを修正する方法として、「ADetailer」という拡張を併用します。使い方は以下の記事を参照してください。

img2imgで画像を動かす
先ほどまでの話はTxt2Imgでしたが、Img2Imgで「AnimateDiff」を使った場合、用意した画像を動かすことができます。

この画像をImg2Imgに放り込み、プロンプトに「cat」とか書いておきます。
適当ニャ。
あとは先ほどと同じように、、「Enable AnimateDiff」にチェックを入れてから「Generate」するだけです。

それっぽく動いたニャ。
プロンプトや「Denoise」と格闘しながらいろいろやってみるといいでしょう。「Denoise」を低くするとオリジナル画像要素が強くなります(低くし過ぎると動かなくなります)。デフォルトの0.7あたりぐらいでいいとは思います。
I2V Traditionalで2枚の画像をつなげて動画にする
始点と終点の画像を用意し、それをつなぎ合わせて動画をつくる方法です。
Img2Imgで、まず始点となる画像を放り込みます。上の画像をそのまま使いましょう。
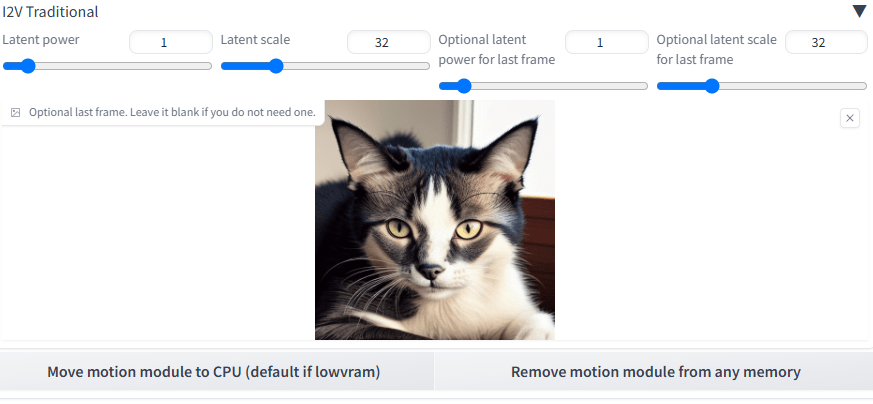
それから「AnimateDiff」の一番下にある「I2V Traditional」を開き、ここに終点の画像を放り込みます。
ここのパラメータですが、以下のようになります。
Latent power:始点画像の影響力の大きさ。
Latent scale:始点画像が始点から何フレーム目まで影響を及ぼすか(数字=フレームではない。あくまで強さ)。
Optional latent power for last frame:終点画像の影響力の大きさ。
Optional latent scale for last frame:終点画像が終点から何フレーム目まで影響を及ぼすか(数字=フレームではない。あくまで強さ)。
このあたりの数字を調整するといいかと思います。

結果がこちら。正面に向き直しているのがわかるかと思います。
ちょっと強引な感じなのニャ。
さきほどのパラメータをいじりながら、ちょうどいい感じにしていくといいでしょう。
経験則としては、「Latent power」「Optional latent power for last frame」は1.5以上で強めにしておかないと、そもそもの始点・終点の画像が反応してくれない感じです。
始点・終点のどちらを強めにするかは、「Latent scale」「Optional latent scale for last frame」をいじるといいでしょう(強めにしたい方の数字を大きく、逆の方は小さく)。両方足して64以下にしたほうがいい感じですが、これも場合によるでしょう。最初のうちはデフォルトでいいとは思います
動画を利用
「Video Source」の欄に動画を放り込み、「ControlNet」の「OpenPose」で動きの骨組みを抽出することで、動画と同じ動きのものを作ることができます。
けっこうメモリを食うので、使用する動画は軽いものを選ぶといいですね。

まとめ

プロンプトを増やせばもうちょっと凝ったものも作れます。ふつうに画像を作るときとおなじようにやればOKです。ただ75トークン以上にならないようにしてください。
それと画像生成でエラーが出てきたら、いったん「Stable Diffusion」を終了して再起動してください。それで直る場合があります。というか、エラーでしょっちゅう動かなくなるので、何度も再起動することになるでしょう。
文字だけで動画が作れるのはすごいのニャ。
「ControlNet」を使ってさらにいろいろ応用することもできます。今回は筆者の環境でうまくいかないので、次回以降にまた記事を上げます。とりあえずプロンプトから動画を作れるというのを楽しんでみてください。【追記】次回「「Deforum」の動画作成方法」できました。以下のリンクから。