Stable diffusionの「ControlNET&拡張機能講座」第15回目。今回は「mov2mov」を使った動画作成です。
なんか時間がかかりそうな感じニャ。
動画は分解すればたくさんの画像の集まりなので、それだけ多くの画像を生成する必要がありますね。時間とPCパワーが必要になってくるジャンルです。
そんなわけで細かい話は抜きで、やり方をさくっと説明していきましょう。前回の「ControlNET版「Inpaint」機能をわかりやすく解説ー画像の一部を修正」は以下のリンクから。

「mov2mov」の導入
「Stable diffusion」を起動し、「Extensions」タブ→「Install from URL」タブに移動し、「URL for extension’s git repository」に、
https://github.com/Scholar01/sd-webui-mov2mov
を貼り付けて、「Install」ボタンをクリックします。しばらく待つと「Install」ボタンの下の方にいろいろ文字が出てきてインストール終了。【追記】次回行う方の動画作成拡張機能のアドレスを貼っていました。修正しました。
つぎに「Extensions」タブ→「Installed」タブで「Apply and restart UI」 ボタンをクリックして再起動します。これでインストール完了です。
(注意)「mov2mov」を導入すると「Img2img」で「ControlNET」を使うときにエラーが出る可能性があります。その場合、「Installed」タブの一覧からチェックを外して再起動してください。「mov2mov」を使うときにまた戻せばよいでしょう。
「mov2mov」の使い方
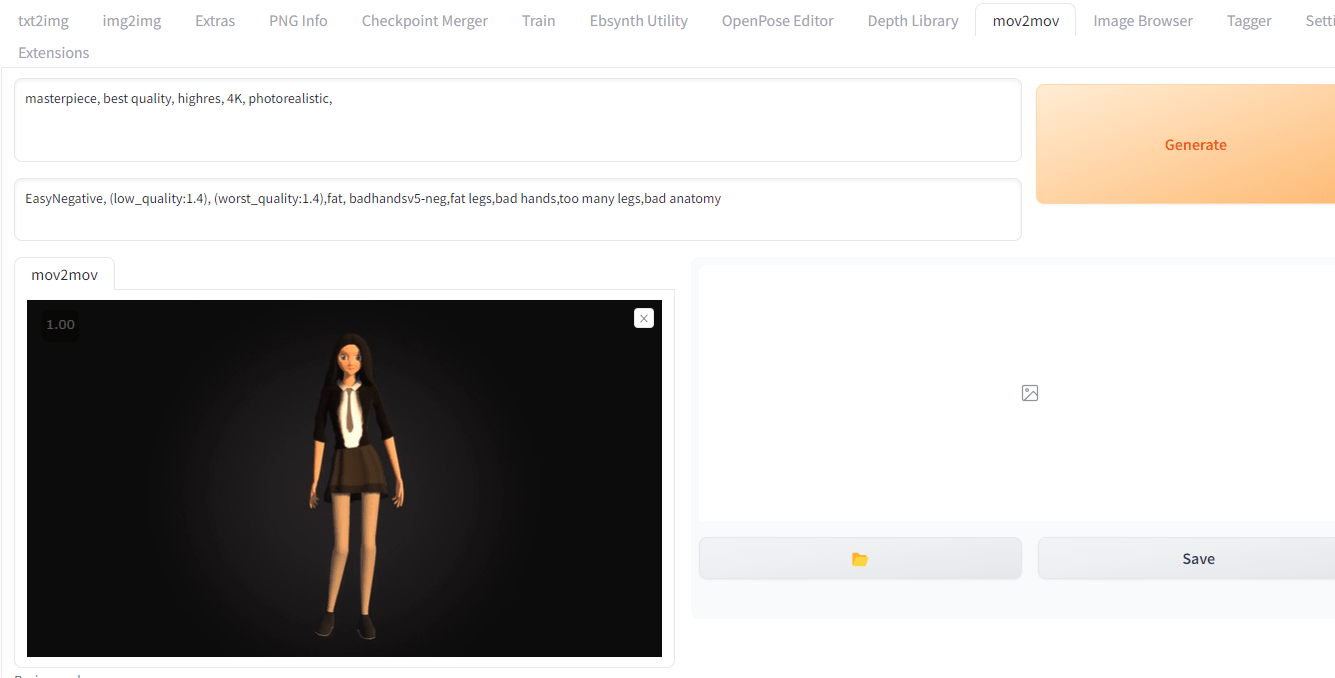
「mov2mov」タブが追加されているので、そこに移動し、動画を放り込みます。今回はPixabayのフリー素材のダンスアニメを利用します。
著作権の問題があるので、動画サイトなどで公開するばあいはフリー素材か自分で適当に踊ってスマホで録画するのがいいでしょう。
自分で踊るのが一番安全なのニャ。
最初は動画を5秒ぐらいに編集しておくといいかもしれません。5秒でも出力にけっこう時間がかかります。理由はあとで述べます。
プロンプトは「1girl,standing,school uniform,fullbody,long hair」など動画にあった内容を適当に書いておきます。
「Resize mode」ですが、「Just resize」(元動画をリサイズする)、「Crop and resize」(元動画を一部切り取ってリサイズする)のどっちかで。初期設定でいいとは思います。
「Sampling method」は自分の好きなもので、「Generate Movie Mode」は出力動画の形式なのでMP4がよければ「MP4V」にでもしておけばよいでしょう。
あとは動画に合わせて「Width」「Height」を設定してください。今回は「768X512」で。
「Denoising strength」も自分の好きなようにいじってください。最初は0.4~0.5ぐらいでやるといいかと。増やすとプロンプトの内容が優先されますが、描画がうまくいかなくなる場合もあります。
その下の「Movie Frames」ですが、1秒に何コマ使うかです。デフォルトは30になっていますが、30はけっこう多くて時間がかかるので、とりあえず10ぐらいに減らしておくといいでしょう。10でも5秒だと50枚生成しなくてはなりません。
時間のかかる作業なのニャ。
ただ10と30だと、動画の質がだいぶ違いますね。10はパラパラ漫画レベルです。時間に余裕があったら30でやったほうがいいでしょう。
あとはいつものように「Generate」ボタンを押すだけですね。長すぎて待ちきれなくなったら「Interrupt」を押して中断してしまってください。途中まででも動画を作成してくれます。
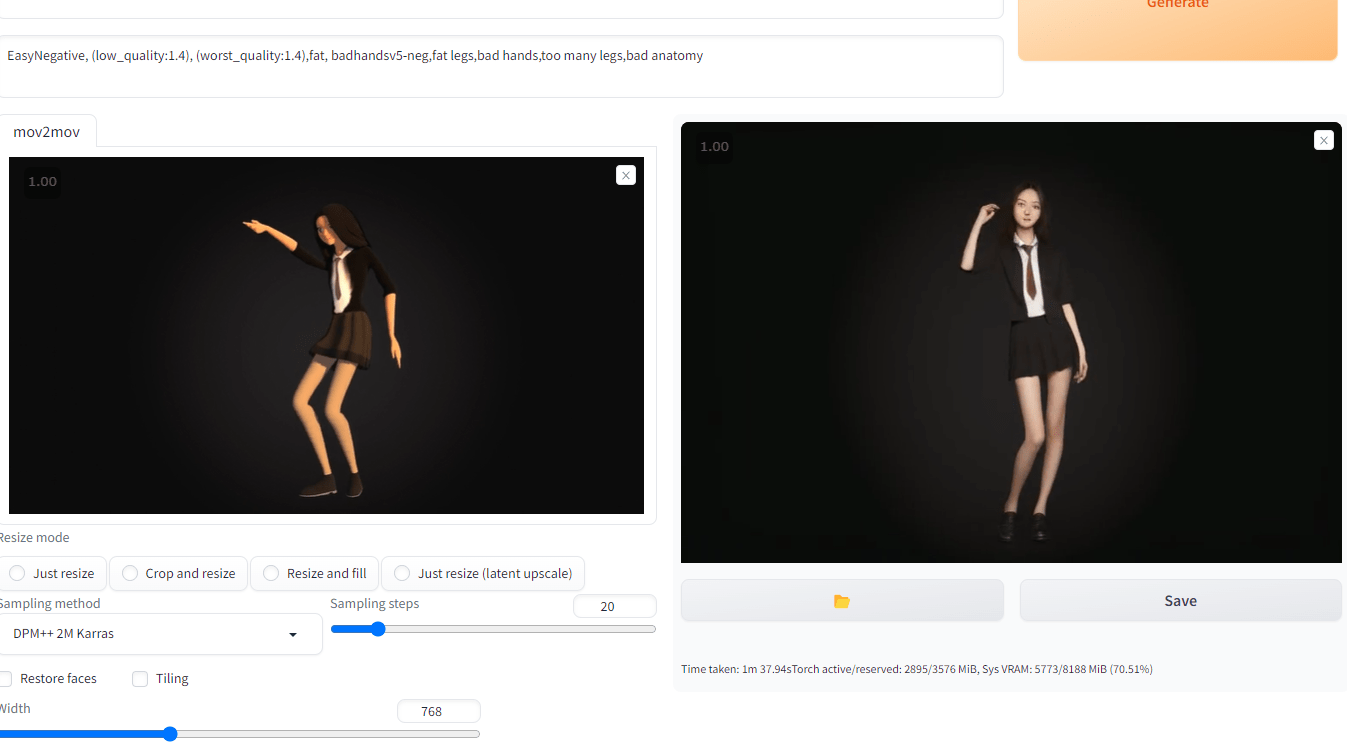
出来上がったのはこちら。
ポリゴン画像が人間っぽい質感になったのニャ。
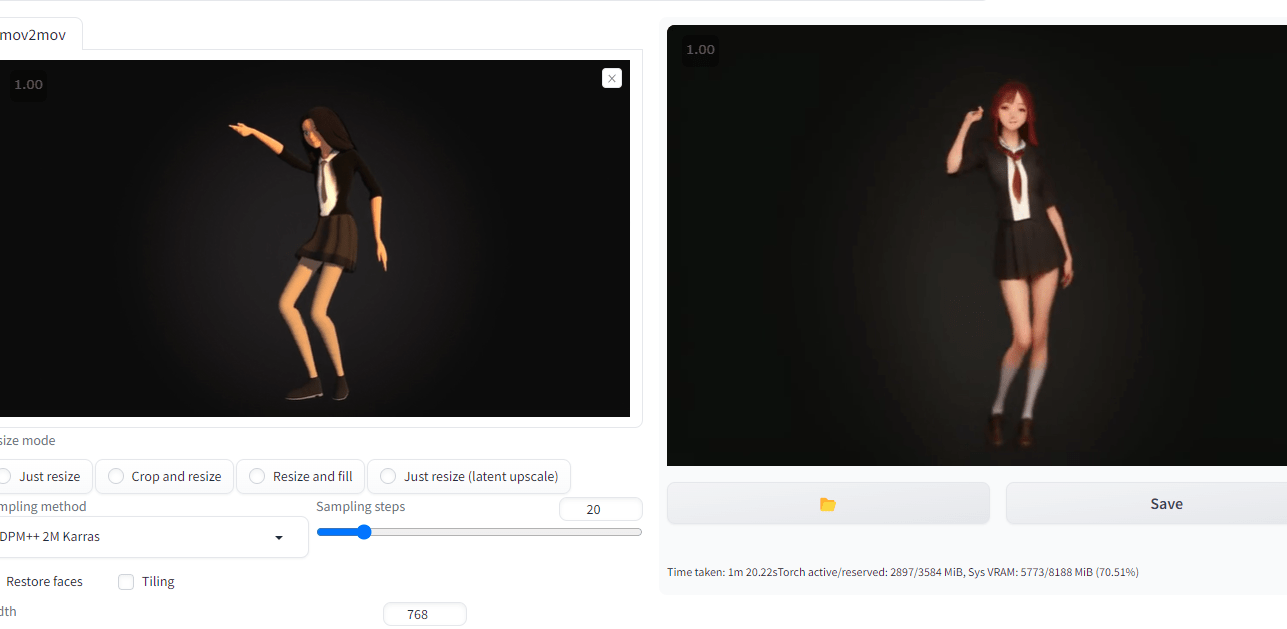
プロンプトに「red hair」を入れて、赤い髪に変更することもできます。
それと前述したようにDenoising strengthを0.4とかに落とすと動画に近くはなりますが、そのかわり画像がぼけます。
しかし0.75にするとプロンプトを優先するので画像ははっきりしますが、元動画から外れたものができあがります。
これを解消するため、Denoising strengthを高く保ったまま、元動画に近い形にするため、「ControlNET」を使います。
「ControlNET」で動画の質を上げる
「ControlNET」をまだ導入していない方は以下のリンクから。

導入している方は「mov2mov」にすでに「ControlNET」があるとは思います。基本的にはなにもする必要はありません。
もし「ControlNET」がなければ、「Setting」タブの「ControlNET」から「Allow other script to control this extension」にチェックを入れてください。そののちに上の「Apply Settings」ボタン→「Reload」ボタンを押します。(注意)「Stable Diffusion」のバージョンによっては、この作業をすることで「mov2mov」の出力がボケボケになることがあります。その場合、チェックを外して「Apply Settings」ボタン→「Reload」ボタンでもとに戻してください。
あとはこの講座で学んできた「ControlNET」の知識を総動員すればよいでしょう。
(設定例1)「lineart」を利用。
・ControlNETを使用するので「Enable」にチェック。
・「Single image」は何も入れなくていい。
・Preprocessorは「lineart_realistic」、Modelは「control_v11p_sd15_lineart」。
・Control Weightは0.4。
・「mov2mov」側のDenoising strengthは0.75(高いほうが画像がはっきりするから)
以上の設定で生成します。
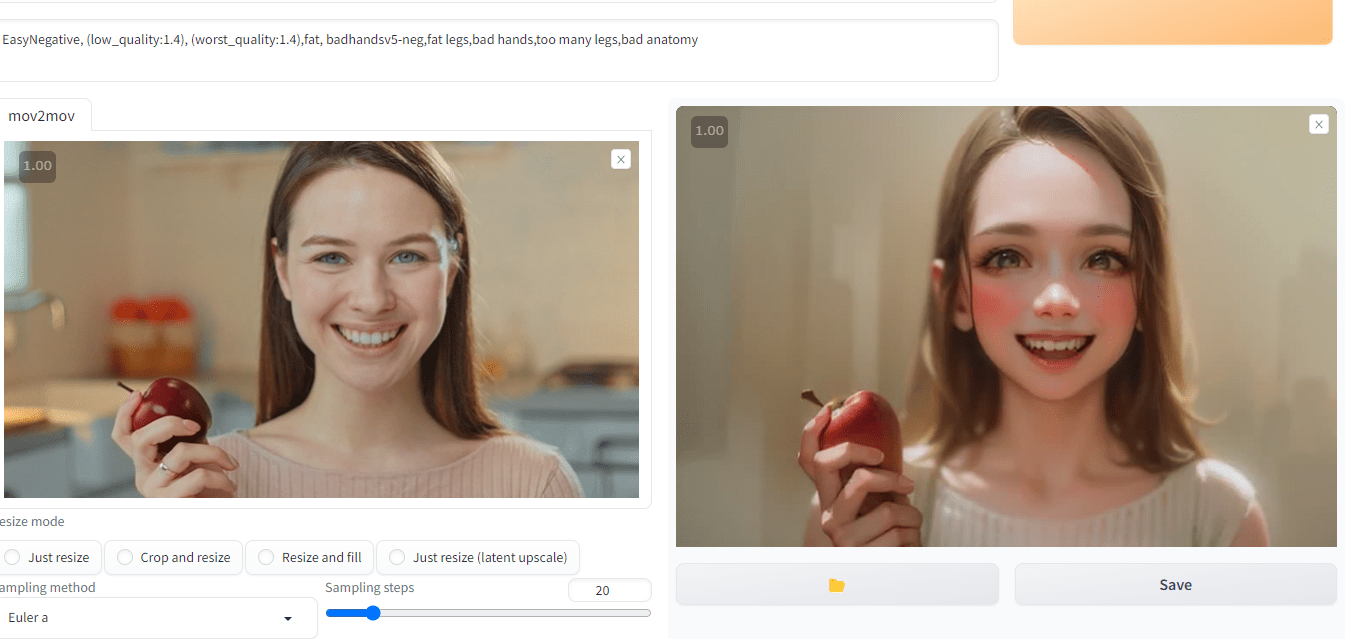
フリー素材の動画を利用しましたが、こんな感じで「lineart」がトレースしてくれます。
けっこう近い感じで再現してくれるのニャ。
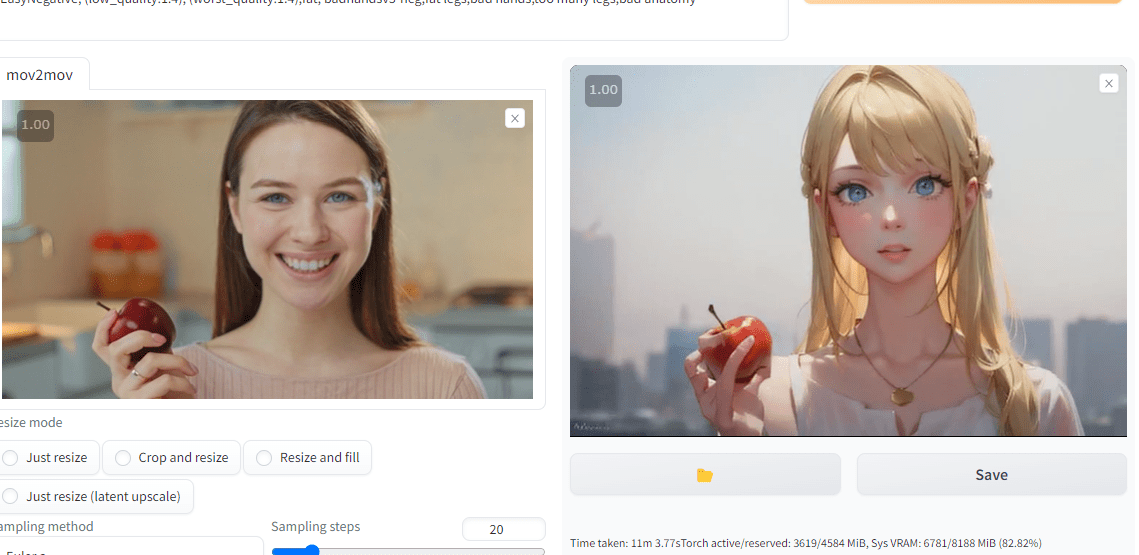
プロンプトで髪の色を変えたり、絵柄を変えたりもできます。
「lineart」自体については以下の記事を参照してください。

「lineart」以外にも、これまで学んできた「Scribble」「Softedge」「Canny」もありますので、いろいろ試してみるとよいでしょう。

それと、動画を作ってみるとわかりますが、コマによって人物が違うばあいもあります(というかそういうのがほとんどです)。
これも以前習ったニャ。人物を統一するには「reference_only」ニャ。
そうですね。「ControlNET」を複数にして、1番目を「reference_only」(参照にする顔画像を「Single image」に入れる)、2番目をさきほどの「lineart」の設定にすればよいでしょう。「reference_only」については以下の記事を参照してください。

コツとしては、まず「lineart」だけで動画をつくり、その中でつかえそうな画像を「reference_only」に放り込んで、「reference_only」+「lineart」で再度動画をつくることによって人物の同一性を保持しやすくなります。
ただ「reference_only」でも同一性を保つのは難しいので、現状はそういうものだと思ったほうがいいでしょう。
動画の動きを保つために、「Openpose」を使うこともできますね。

なんにしろ、現状はそこそこなものができれば十分といった感じです。完璧なものをつくろうと思わず、気楽遊ぶぐらいでいいですね。
「Openpose」「reference_only」をがんばっても、背景のある動画だと背景は統一されませんし、現状は「lineart」だけで十分とは思います。動画処理にも時間がかかりますしね。
まだまだ発展途上の技術なのニャ。
「sd-dynamic-thresholding」で質を上げる
拡張機能「sd-dynamic-thresholding」を使って、質を上げることも可能です。
「mov2mov」を導入したのと同じ手順で、
https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
を張り付けて導入してください(再起動を忘れずに)。
これをするとCFG Scaleを7以上にしても破綻しにくくなります。
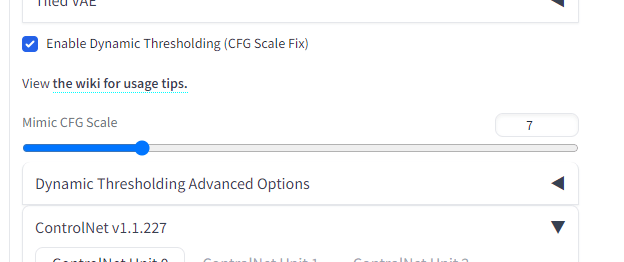
使用するときはControlNETの上あたりにある「Enable Dynamic Thresholding (CFG Scale Fix)」にチェックを入れます。あとは上のCFG Scaleをいじるなり、チェックマークのすぐしたのMimic CFG Scaleをいじるなりしてください。
CFG Scaleを12~15、Mimic CFG Scaleを5~7にすると改善するらしいです(あくまで可能性の問題です)。
ちなみに筆者の環境だとあまり変わらないかなという感じでした。むしろデフォルトの7が一番きれいでした。これはつかうモデル(チェックポイント)に左右される部分とは思います。
まとめ
とにかく生成に時間がかかるので、最初は短い動画でやったほうがいいですね。
30フレームだと、1秒で30枚ですし、とんでもなく時間がかかります。
ハイスペックなグラボが必要になるのニャ。
ただ30フレームないとパラパラ漫画感が強くなりますね。
次回の講座は「EBsynth」を利用した動画作成を予定していたのですが、けっこう複雑で逆に混乱させる可能性があるので次回は「Image Browser」の講座にして、「EBsynth」は後日作ることにしました。【追記】「「EBsynth」と「Stable diffusion」で動画を作る方法をわかりやすく解説ー背景変更についても」できました。以下のリンクから。
次回は画像作成の生産性を上げる「「Image Browser」で画像管理する方法をわかりやすく解説」です。以下のリンクから。